O desafio dos milissegundos: como escalar decisões de flags para milhões de usuários sem estourar o seu banco de dados
Como construímos uma arquitetura de cache híbrido L1/L2 com invalidação reativa em tempo real para blindar seu banco de dados contra o temido Thundering Herd Problem.
Avaliar feature flags em escala planetária parece simples no papel: basta um 'if' condicional. Mas quando o seu sistema processa milhões de requisições por segundo, essa verificação simples vira um pesadelo de rede. Se cada verificação de flag bater diretamente no seu banco de dados relacional ou exigir uma consulta externa de rede por usuário, sua infraestrutura vai colapsar sob o efeito do Thundering Herd Problem.
Quando um pico de tráfego ocorre e o cache expira, milhares de requisições concorrentes tentam ler a mesma regra de flag simultaneamente do banco de dados principal. O resultado? Pool de conexões saturado, latência no P99 disparando e, eventualmente, downtime generalizado. Para resolver isso, a Useflagly aborda a consistência e a distribuição de regras de um jeito fundamentalmente diferente.
A arquitetura de invalidação reativa: rules version (rv) e redis pub/sub
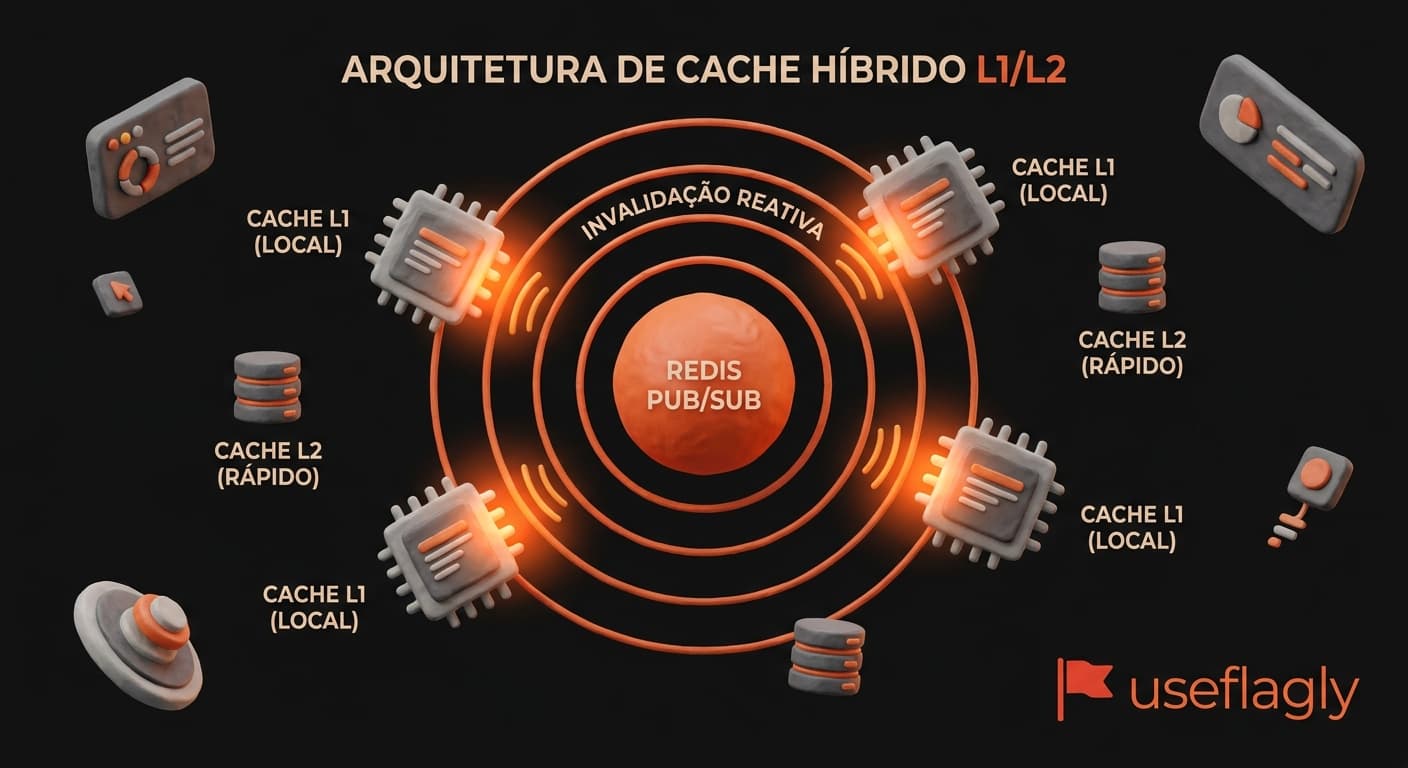
Para mitigar o gargalo de rede sem introduzir dados obsoletos (stale data), a Useflagly opera com um modelo híbrido de cache distribuído em duas camadas. No nível do SDK e do servidor de borda, implementamos um cache L1 em memória de processo (LRU) pareado com um cache L2 distribuído via Redis. O segredo da consistência instantânea reside no nosso mecanismo de Rules Version (rv).
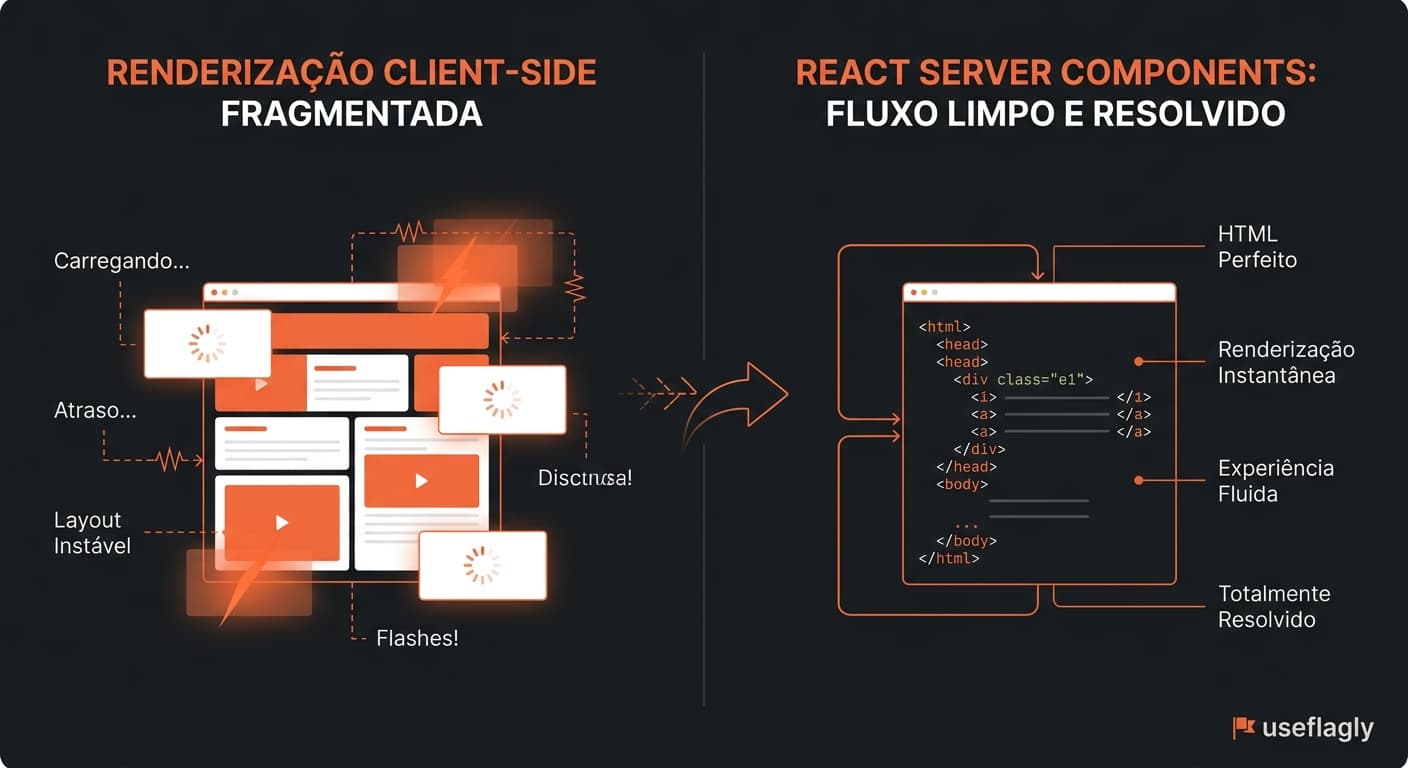
Quando você altera as regras de uma Flag no painel, o Useflagly incrementa o 'rv' e dispara uma mensagem ultra-leve via Redis Pub/Sub. Em milissegundos, todas as instâncias de borda e de cache L1 são notificadas reativamente para invalidar aquela chave específica. Esse desacoplamento protege seu banco de dados transacional: a consulta pesada só acontece uma vez durante a persistência. Toda a organização lógica em Scenario, Flow e FlowPart serve estritamente para estruturar seu painel visualmente. O motor de execução otimizado garante que as validações e lógica residam unicamente na Flag. Assim, reduzimos o parsing de regras complexas ao mínimo absoluto, resolvendo o hot path em tempo de execução sub-milissegundo.
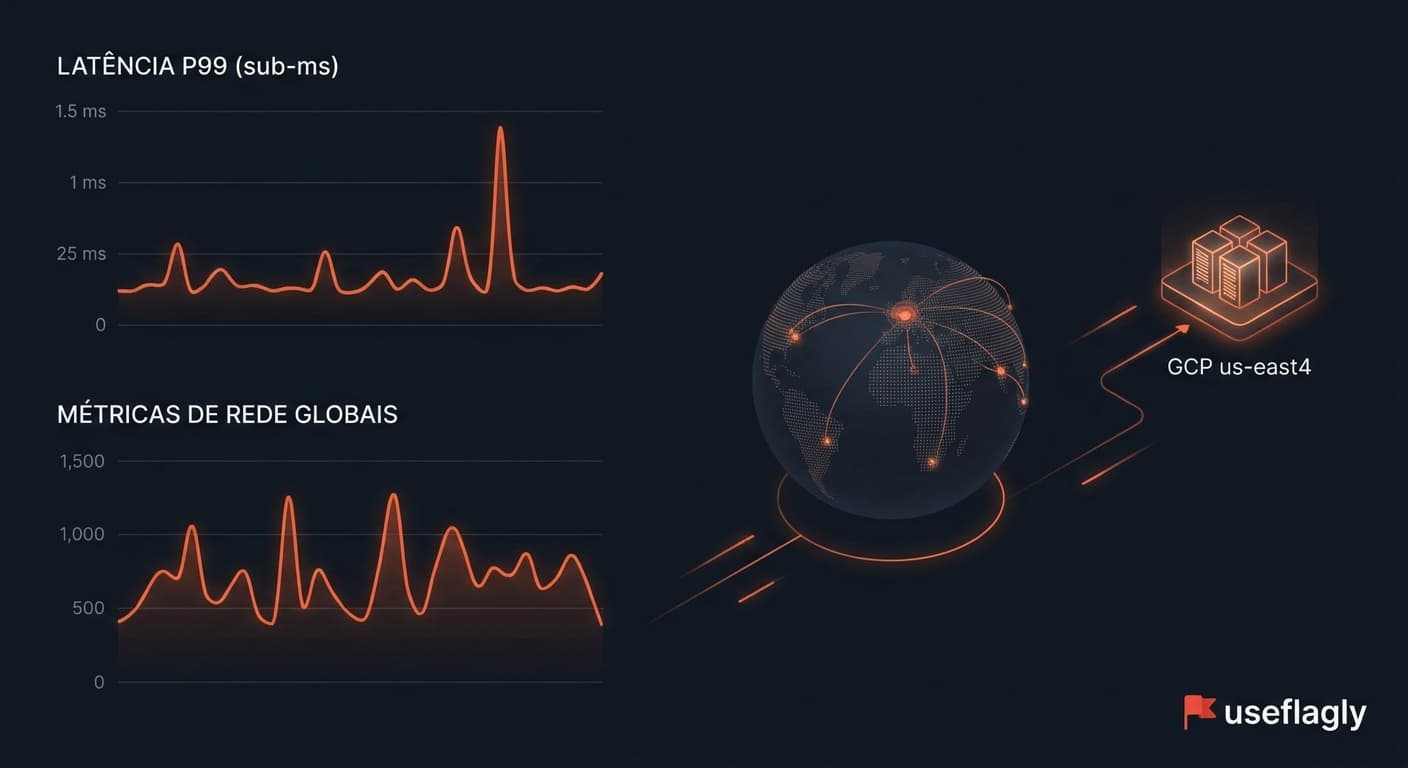
Garantia de p99 sub-milissegundo na infraestrutura us-east4
Performance de rede em sistemas de alta disponibilidade não tolera longas distâncias físicas. É por isso que a infraestrutura core da Useflagly está estrategicamente hospedada no Google Cloud Platform (GCP) na região us-east4 (Norte da Virgínia). Ao aproximar nossos microsserviços de borda e réplicas Redis dos maiores provedores de nuvem do mundo, garantimos rotas de rede ultracurtas.
Mesmo sob picos severos de tráfego, o uso combinado de caches L1/L2 com invalidação reativa via Redis garante que mais de 99.9% das verificações de flags sequer precisem sair da memória do servidor. O resultado prático para o seu sistema é um tempo de resposta de P99 na casa dos milissegundos, sem comprometer a consistência das suas decisões de negócio e mantendo seus custos operacionais de infraestrutura estáveis.
⚠️ ⚠️ Lembre-se: no ecossistema Useflagly, entidades como Scenario, Flow e FlowPart servem unicamente para organizar e segmentar seu painel de forma visual. Toda a lógica de avaliação de regras, validações e dados de controle de cache residem exclusivamente na Flag, o que garante a máxima performance sob cargas intensas.
🚩 useflagly.com.br